Four frontier AI models dropped inside a single month not long ago. Four. New flagship releases from the big labs, landing within weeks of each other, each one claiming the crown for a few days until the next release knocked it off.
If your product hard-wires one of them into every layer of your stack, you felt those weeks as stress. You watched a cheaper, faster, smarter model show up... and you couldn't touch it without a rewrite. A self-inflicted wound, and I want to talk about how to stop doing it to yourself.

The model under your app is now the fastest-moving part
For most of my career, the slow-moving parts of a system were the engines underneath. Your database didn't get 40% better every quarter. Your web framework didn't triple in capability in six months. You picked one, you learned its edges, and it stayed roughly the same for years.
The AI model is the opposite. It is the single fastest-moving dependency you have ever shipped on. Pricing shifts. Context windows grow. A model at the state of the art in February sits mid-tier by spring. And a new provider you'd never heard of turns up offering the same quality for a fraction of the price.
So here is the question I keep asking founders and engineering leads: when the next better model drops, how long does it take you to switch? If the honest answer is "weeks," you have built your house on the one patch of ground moving the most.
Lock-in creeps in, it doesn't announce itself
Nobody decides to get locked in. It happens in four quiet steps.
You pick a provider. You start using its handy provider-specific features. Your business logic gets tangled up with the provider's SDK and its particular way of describing tools. Then, months later, you go to switch and meet the cost.
One write-up I read from Bluebag on avoiding LLM lock-in puts the switching cost at two to three months of engineering work. It matches what I've seen. By the time switching hurts, the tangle is everywhere, and "let's migrate" turns into a quarter you didn't plan for.
The risks aren't theoretical either. Pricing shifts under you... OpenAI has changed its pricing more than once, and Google has been happy to subsidise Gemini to win share. Every API goes down sometimes. Anthropic, OpenAI, Google... all of them. And if you sell into regulated markets, data residency rules take a provider off the table overnight, no matter how good the model is.
Build the seam on purpose
The fix is old-fashioned software engineering. You put a seam between your application and the model. One thin layer your whole app talks to, and behind it, small adapters each knowing how to speak to a specific provider.
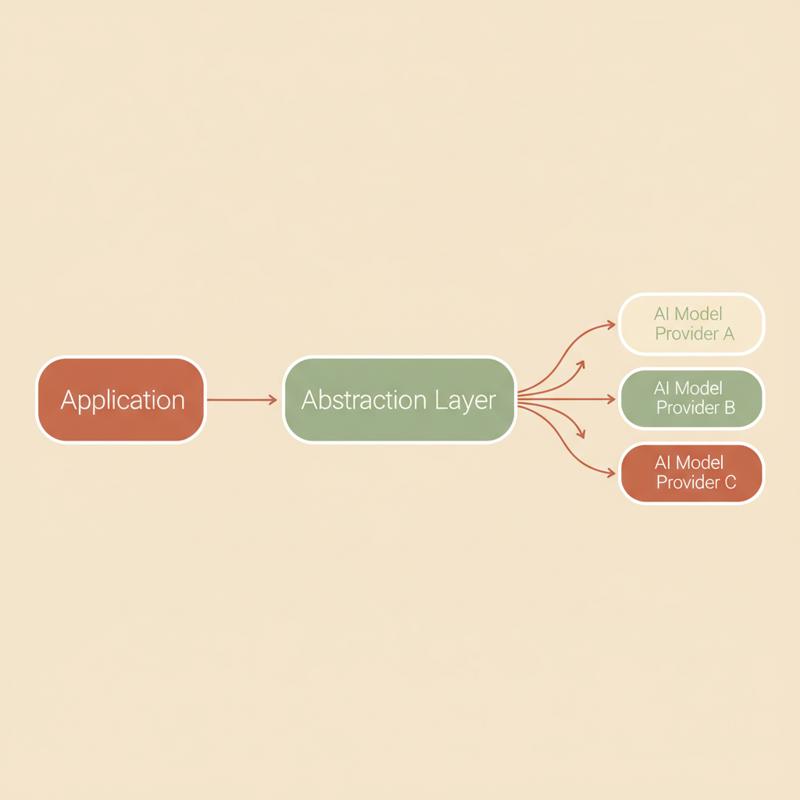
It isn't complicated. A good provider-agnostic abstraction layer needs four things:
- A common interface. One contract... something like
chat(), plus a way to ask which model you're running. Every provider hides behind it. - Adapters per provider. Small translators turning your standard call into whatever OpenAI, Anthropic, Gemini, DeepSeek, or a local model wants to hear.
- A client wrapper. The piece picking an adapter and reporting back what each call cost and how long it took.
- Measurement. Token counts, latency, and price per request, captured every time so you compare like for like.
Get this right and switching a model stops being a migration. It becomes a configuration change. And there's the whole game. The same source benchmarking six providers side by side makes the point plainly: without abstraction, "provider switching requires weeks of refactoring. With it, it's a configuration change."
The money is real, not a rounding error
I'm wary of vendor savings claims, so let me stick to numbers I point at directly.
The benchmark ran the same prompt across six providers and the spread was wild. Groq running a Qwen model came back in 6.4 seconds. A reasoning model from DeepSeek took 36.2 seconds for the same job. Cost per request ranged from a fraction of a cent to ten times more, depending purely on which engine you routed to. Same prompt. Same output expectation. Ten-fold difference.
The list prices tell the same story. Going on the figures in the lock-in write-up: GPT-3.5 Turbo at $0.50 per million tokens, GPT-4o at $2.50, Gemini 1.5 Pro at $1.25, and Claude Opus up at $15.00. If you send every request to the most expensive model out of habit, you are setting money on fire. Route reasoning to the strong model, route the simple, high-volume work to the cheap fast one, and your average cost drops hard.
The same article claims task-specific routing takes an average blended cost from around $10 per million tokens down to roughly $3. I'd treat the exact figure as illustrative rather than gospel... your traffic mix decides your real number. But the direction is not in doubt. You do none of this routing if your app only knows how to talk to one provider.
What the seam buys you beyond cost
Once you've got the layer, four useful patterns fall out almost for free.
A router. Send each task to the model suiting it. Heavy reasoning to one, raw speed to another, giant-context jobs to a third.
A fallback chain. When one provider has a bad afternoon, you fail over automatically instead of failing over loudly to your customers.
A/B testing across providers. Run the new model against the old one on real traffic and let the metrics, not the hype thread, tell you whether it wins for your use case.
Consensus for the critical calls. For the decisions truly mattering, ask more than one model and compare. Expensive, so you reserve it... but you reserve it only if the wiring already exists.
None of these are exotic. They are the same resilience patterns we've used for databases and payment providers for twenty years. The one new thing is the dependency underneath changing faster than anything we've dealt with before.
You don't need to abstract everything on day one
A fair pushback: isn't this premature abstraction? Aren't we always told to hold off on the flexible thing until we need it?
Usually, yes. Here, I think the calculus has flipped. The model layer changes monthly. The cost of the seam is small... a thin interface and a couple of adapters, a day or two of work. The cost of skipping it is a multi-month migration at the worst possible moment, usually when a competitor has already shipped on the cheaper, better model you've been locked out of.
You don't have to support six providers from the start. Support one, but talk to it through the seam. Make the second adapter a half-day job for whoever needs it. The point isn't to use every model... it's to make using the next one cheap.
The real moat isn't the model
Everyone is building on the same handful of frontier models. The model is not your advantage. It's a commodity engine you rent, and the rental market reprices every few weeks.
Your advantage is your product, your data, your judgement about which engine fits which job, and your ability to swap engines faster than the people you compete with. The teams treating the model as a fixed foundation are the ones rewriting code every time the ground shifts. The teams treating it as a swappable part are the ones quietly upgrading with a config change and pocketing the difference.
So go look at your own stack. When the next better model drops next month... and it will... how long until you're running on it? If the answer isn't "an afternoon," you know what to build next.